XTriples
A generic webservice to extract RDF statements from XML resources.
Documentation
Background
The extraction of RDF statements from XML data can be a complicated process involving a lot of XSLT magic. Transformations are always specific to the XML data in question and cannot easily be applied to other XML repositories. It gets even more difficult if the markup of the XML data in question cannot be influenced.
However, the underlying principle of creating RDF statments out of XML data is simple.
- If we take a XML resource or a value in it as the thing we want to talk about, this is our subject.
- We want to join this subject to "something else" using a predicate from a controlled vocabulary.
- This "something else" is our object, consisting either of the XML resource itself, some value in it or some other resource on the semantic web.
The XTriples webservice makes it possible to create such statements out of any XML data based on a simple XML configuration. The configuration defines the XML resources to crawl, the vocabularies to use and a number of XPATH/XQuery based statement patterns to apply on the data.
The webservice accepts POST or GET request to https://xtriples.lod.academy/extract.xql.
Requests
POST requests
You can submit POST requests to https://xtriples.lod.academy/extract.xql
The request body should contain your XTriples configuration. Additionally, you need to send the Content-Type HTTP header with a value of application/xml and the format HTTP header with one of the following values:
Reference
| value | result |
|---|---|
| rdf | returns extraction result as RDF |
| turtle | returns extraction result in Turtle notation |
| ntriples | returns extraction result as N-Triples |
| nquads | returns extraction result as N-Quads |
| trix | returns extraction result as TriX named graph |
| json | returns extraction result as JSON-LD |
| svg | returns extraction result as SVG Graph |
| xtriples | returns extraction result as XTriples XML for extractging purposes |
If you send no format header, the format defaults to rdf.
GET requests
The most compact way to use the webservice is via HTTP GET requests. This is the URL scheme:
https://xtriples.lod.academy/extract.xql?configuration=###YOUR_URI###&format=###FORMAT_KEYWORD###
The keywords for the format parameter are the same as for direct POST requests (see above).
Basic configuration
A configuration consists of a simple XML structure that tells the webservice which XML collections to crawl and which statements to extract from each resource of a collection. It has three relevant areas.
Code
<xtriples>
<configuration>
<vocabularies>
[1]
</vocabularies>
<triples>
<statement>[...]</statement>
<statement>[...]</statement>
<statement>[...]</statement>
[2]
</triples>
</configuration>
<collection>
[3]
</collection>
</xtriples>
Below <collection> you configure the XML data that should be processed by the service. Below <vocabularies> you can configure the RDF vocabularies you would
like to use. Below <triples> you configure one ore more <statement> patterns that contain your subjects, predicates and objects.
The <collection> tag
A collection consists of XML data. It can be a single XML file
with repeating nodes that represent the "resources". It can also be a XML based list of URLs pointing to single XML resources.
During extraction the webservice
crawls over all resources of a collection and applies the configured statements patterns to each XML resource.
It is possible to use several <collection> tags per configuration.
Reference
| attributes | required | values | description |
|---|---|---|---|
| uri | no | string | The XML of the collection will be fetched from this URI if it is not submitted literally to the webservice. |
| max | no | integer | When set the extraction will stop after the number of resources set in this attribute. |
There are three methods for crawling the resources of a collection: XPATH based, link based and literal.
Note: It is possible to mix the three methods within a <collection> tag.
XPATH based resource crawling
XPATH based resource crawling is an automatic way of extracting XML resources. It is very handy if you want to crawl a collection with an unkown number of resources.
The XPATH constructs the path to the XML resources of a collection. You specify it with curly braces in the uri
attribute of a child <resource> of your <collection> tag.
Code
<xtriples>
<configuration>
[...]
</configuration>
<collection uri="http://xml.collection.somewhere/resources.xml">
<resource uri="http://xml.collection.somewhere/resources/{//id}.xml" />
</collection>
</xtriples>
In this example, the uri attribute of the <collection> tag points to a XML file that contains
a list of IDs of XML resources to harvest. During extraction, this list provides the context for the expression
in the uri attribute of the child <resource> tag. The attribute of the <resource>
tag contains a URL. At any position within the URL string you are allowed to use XPATH expressions in curly braces that will be
executed on the XML of the <collection>. In the above example, the service will walk through all ids
found by the XPATH expression in the <collection> and substitute the curly brackets, building correct links to XML resources.
Example 1: XPATH based resource crawling with resources all in one single file
Example 2: XPATH based resource crawling with resources spread over multiple files
Link based resource crawling
Link based resource crawling works by submitting <resource> tags below the <collection> tag with complete URLs to the XML files..
This approach is handy if you know all URLs of a collection in advance or if you want to crawl a fixed number of resources.
Just add any number of resource tags below the <collection> tag with the link to the according resource in the
uri attribute. Here is an example:
Code
<xtriples>
<configuration>
[...]
</configuration>
<collection>
<resource uri="http://xml.collection.somewhere/resources/1.xml" />
<resource uri="http://xml.collection.somewhere/resources/2.xml" />
<resource uri="http://xml.collection.somewhere/resources/3.xml" />
</collection>
</xtriples>
This will make the webservice crawl the three resources in question.
Example 3: Link based resource crawling with fixed resources in the configuration file
Literal resource crawling
Crawling of literal XML resources is the fastest way of extracting statements. In this approach the XML resources are submitted literally to the webservice.
Just submit any well formed XML below a <resource> tag.
Code
<xtriples>
<configuration>
[...]
</configuration>
<collection>
<resource>
<!-- Any wellformed XML -->
</resource>
<resource>
<!-- Some more wellformed XML -->
</resource>
</collection>
</xtriples>
Example 4: Literal resource crawling with XML resources
The <vocabularies> tag
Below the <vocabularies> tag you can configure any number of RDF vocabularies you would like to use for your statements.
Its comparable to the header of a SPARQL query where you declare your vocabularies. Each <vocabulary> tag can have the
following attributes.
Reference
| attributes | required | values | description |
|---|---|---|---|
| prefix | yes | string |
Sets the prefix for the vocabulary. This prefix can then be used in the prefix attribute
of a <subject>, <predicate> or <object> tag
(see below).
|
| uri | yes | xsAnyURI | Sets the URI for the vocabulary. |
Code
<xtriples>
<configuration>
<vocabularies>
<vocabulary prefix="rdf" uri="http://www.w3.org/1999/02/22-rdf-syntax-ns#"/>
<vocabulary prefix="dc" uri="http://purl.org/dc/elements/1.1/"/>
<vocabulary prefix="owl" uri="http://www.w3.org/2002/07/owl#"/>
</vocabularies>
[...]
</configuration>
[...]
</xtriples>
The <triples> tag
Below the <triples> tag you can define any number of <statement> patterns for the extraction.
The statement patterns are the core of the XTriples webservice.
<triples>
<statement>[...]</statement>
<statement>[...]</statement>
<statement>[...]</statement>
</triples>
The <statement> tag
Each <statement> consists of exactly one <subject>, <predicate> and
<object> tag. An optional <condition> tag is allowed. Together they form a statement pattern that
will be applied to each XML resource that is crawled by the webservice.
Reference
| attributes | required | values | description |
|---|---|---|---|
| repeat | no | integer and/or {XPATH/XQuery} |
This will repeat the extraction of the statement pattern as many times as the number set in the attribute. The value of the current
iteration is written to the $repeatIndex variable. The attribute can contain a valid XPATH/XQuery expression in curly braces that
must result in an integer (no node sets allowed).
|
Code
<statement>
<subject prefix="resource">//id</subject>
<predicate prefix="rdf">type</predicate>
<object prefix="skos" type="uri">/string("Concept")</object>
</statement>
The code above results in a skos statement for each resource from the configured XML repository.
Example 5: FOAF statement for one resource
The <subject> tag
The <subject> tag of a statement pattern can either result in an URI or a blank node. In case of a blank node the blank node
must have been created already by an earlier <object> tag.
Code
<statement>
<subject prefix="###MY_VOCABULARY_PREFIX###">//id</subject>
[...]
</statement>
In the above example, the XPATH expression will fetch the id value from each crawled resource. It is used together with the prefix attribute
to construct the subject URIs.
Reference
| attributes | required | values | description |
|---|---|---|---|
| prefix | no | string |
The prefix attribute can contain a value
defined in one of the vocabularies' prefix attributes. This binds the <subject> to a <vocabulary>
namespace. During exraction the value of the prefix attribute is substituted with the URI that has been defined
for the vocabulary's uri attribute. Similar to the prefix concept known from SPARQL.
|
| type | no |
|
Only needed for connecting blank nodes. When you set the type of a <subject> tag to bnode, then you should
apply the same identifier that has already been created by an earlier <object> tag expression. This will make the former
object (blank node) the subject of a new statement.
|
| resource | no | xsAnyURI |
If you set the resource attribute to a valid URL for an external XML document, this URL will be fetched during extraction and the <subject>
XPATH/Xquery will be executed on the external XML rather than the XML of the current resource.
|
| prepend | no | string + {XPATH/XQuery} |
The prepend attribute is handy if you need to prepend a value to the current patterns XPATH/XQuery result. The attribute value should contain
a valid XPATH/XQuery expression in curly braces that results in a string (no node sets allowed). This expression will be executed after the <subject>
expression and it's result will be prepended to the overall result.
|
| append | no | string + {XPATH/XQuery} |
The append attribute works the same as the prepend attribute only that the result will be appended to the overall result.
|
Examples
Example 6: Extracting a subject URI
Example 7: Creating a subject blank node
Example 8: Including a value from an external XML resource in the subject
Example 9: Prepend and append values to the subject result
The <predicate> tag
The <predicate> tag of a statement pattern contains the property URIs of the vocabularies defined in the <vocabularies>
section of the configuration. The final result of a predicate expression must always be an URI.
The predicate tag mostly contains simple property strings. But it is also possible to execute an XPATH/XQuery in the tag or
retrieve a value from an external XML resource by using the <resource> attribute.
Code
<statement>
[...]
<predicate prefix="###MY_VOCABULARY_PREFIX###">###MY_PROPERTY###</subject>
[...]
</statement>
Reference
| attributes | required | values | description |
|---|---|---|---|
| prefix | yes | string |
The required prefix attribute of the <predicate> must contain a value defined in a vocabulary's prefix attribute.
This binds the <predicate> to a <vocabulary> namespace.
The value of the prefix attribute is substituted with the URI that has been defined in the vocabulary's uri attribute.
|
| resource | no | xsAnyURI |
If you set the resource attribute to a valid URL for an external XML document, this URL will be fetched during extraction and the <subject>
XPATH/Xquery will be executed on the external XML rather than the XML of the current resource.
|
| prepend | no | string + {XPATH/XQuery} |
The prepend attribute is handy if you need to prepend a value to the current patterns XPATH/XQuery result. The attribute value should contain
a valid XPATH/XQuery expression in curly braces that results in a string (no node sets allowed). This expression will be executed after the <predicate>
expression and it's result will be prepended to the overall result.
|
| append | no | string + {XPATH/XQuery} |
The append attribute works the same as the prepend attribute only that the result will be appended to the overall result.
|
The <object> tag
The <object> tag of a statement pattern can either result in an URI, a literal value or a blank node. Literal values
can be typed or tagged with a language code. In case of a blank node, the object expression should lead to a
unique identifier for the node.
Code
<statement>
[...]
<object prefix="###MY_VOCABULARY_PREFIX###" type="uri">###MY_VALUE###</object>
[...]
<object type="literal" lang="en">###MY_VALUE###</object>
[...]
<object type="literal" datatype="integer">###MY_VALUE###</object>
[...]
<object type="bnode">###MY_UNIQUE_ID###</object>
</statement>
Reference
| attributes | required | values | description |
|---|---|---|---|
| prefix | no | string |
If the result of the <object> tag is a URI, the prefix attribute can be used to bind
the <object> to a defined <vocabulary> namespace. The value of the prefix
attribute is substituted with the URI that has been defined in the according vocabulary's uri attribute. Similar
to the prefix concept known from SPARQL.
|
| type | no |
|
If the value is set to uri, the final result of the object expression should be a xsAnyURI. The <prefix>
attribute can be used to bind a vocabulary namespace to the object value. Alternatively, you can of course construct or extract full
URIs out of values in the current resource's XML without using a prefix. If the value is set to literal, a plain string value
is expected as the result of the object expression. This value can then be typed using the <datatype> attribute
or tagged with a language attribute by using the <lang> attribute. If the value is set to bnode the result
of the object expression should be a unique identifier (see below for more details about blank nodes and some examples).
|
| resource | no | xsAnyURI |
If you set the resource attribute to a valid URL for an external XML document, this URL will be fetched during extraction and the <subject>
XPATH/Xquery will be executed on the external XML rather than the XML of the current resource.
|
| lang | no | ISO code | You can language tag your object literals by using this attribute. Set the attribute value to one of the ISO language codes. |
| datatype | no | XML Schema datatype | You can type your object literals with this attribute. The attribute value can contain any of the official data types from XML schema (like integer, float, double, decimal, time, date etc.) |
| prepend | no | string + {XPATH/XQuery} |
The prepend attribute is handy if you need to prepend a value to the current patterns XPATH/XQuery result. The attribute value should contain
a valid XPATH/XQuery expression in curly braces that results in a string (no node sets allowed). This expression will be executed after the <object>
expression and it's result will be prepended to the overall result.
|
| append | no | string + {XPATH/XQuery} |
The append attribute works the same as the prepend attribute only that the result will be appended to the overall result.
|
Example 10: Creating an object URI
Example 11: Creating a typed object literal
Example 12: Creating a language tagged literal
Example 13: Including a value from an external resource in the object
The <condition> tag
Sometimes a statement pattern should only be applied to resources if a specific condition matches. The <condition> tag allows you to define an expression and only if the result returns TRUE the statement pattern will be applied to the resource.
Code
<statement>
<condition>/image</condition>
<subject type="uri">/image/@url</subject>
<predicate prefix="rdf">type</predicate>
<object prefix="foaf" type="uri">Image</object>
</statement>
The above statement pattern would only be applied to resources that have an image tag. If there is no image tag, the XPATH returns empty and the statement pattern is not executed.
Example 14: Applying a <condition> to a statement pattern
Advanced configuration
Context variables
The context node for each subject/predicate/object expression is always the resource that is currently crawled.
You can reference it with "." in your expressions or by using the $currentResource variable. When crawling
single file repositories where resources consist of repeating nodes in one XML, it is also possible to walk
above the resource node by using "..".
Reference
| variable | description |
|---|---|
| $currentResource |
The $currentResource variable contains the full XML content of the current resource. It can be used in all XQuery
functions and XPATH expressions of the XTriples webservice (see example below).
|
| $externalResource |
Same as $currentResource but for contexts where you load an external XML resource instead of the current one using the resource
attribute in a subject, predicate or object tag.
|
| $resourceIndex |
The $resourceIndex variable contains the number of the XML resource currently crawled.
|
| $repeatIndex |
The $repeatIndex variable contains the number of the extraction iteration triggered by the repeat attribute
of a statement pattern.
|
Example 15: Using the $currentResource variable in statement patterns
Example 16: Using the $repeatIndex variable in statement patterns
1:n statements
It is possible to create 1:n statements with a single statement pattern. This happens automatically when an XPATH/XQuery
in the object part of a statement pattern yields a node set. The subject and predicate are then repeated for each node of the result set, creating n statements in total, each with
the same subject and predicate but with different object values.
Example 17: Creating a 1:n statement with an object node set
n:1 statements
Example 18: Creating a n:1 statement with a subject node sets
It is also possible to create n:1 statements with a single statement pattern. The technique is the same as with 1:n statements, with the difference
that this time the XQuery/XPATH of the subject part of the statement pattern yields a node set. The predicate and object are then repeated for each node of the
result set using a different subject value.
n:m statements
In a use case where n-subjects should be bound to m-objects with a single statement pattern, the same rules as described above apply. In a n:m case both, the subject
and the object expressions yield node sets. The webservice then iterates over all nodes of the subject result set and connects them to all nodes from the object
result set.
Example 19: Creating n:m statements in a single statement pattern
Error handling and debugging
Quite naturally when writing XPATH/XQuery expressions on a given XML, there will be some errors (like typecast errors etc.) or unexpected results (like empty node sets etc.). XTriples tries to handle such errors transparently. The strategy is not to terminate query execution due to a fatal error but to catch it and then pass a meaningful error description back to the user.
The easiest way to debug unexpected outcomes is to use the internal XTriples result format. This format is generated right before the transformation to RDF and contains all results of all statement expressions in a structure similar to the original configuration.
In this format it is easy to identify XPATH expressions for subjects, predicates or objects that came out empty or see the error messages thrown by XQuery functions.
All that needs to be done to get the internal format for debugging is to append the call to the webservice with a &format=xtriples parameter.
Example 20: Using the internal xtriples result format for debugging purposes
Webservice components
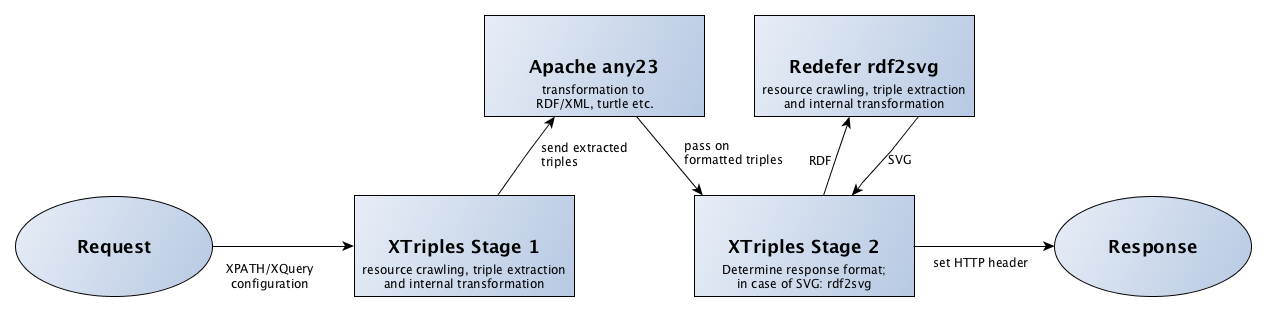
XTriples is built on top of some great software packages. The foundation for XTriples is the eXist XML database. The RDF transformations are done with the Apache any23 webservice. For SVG graph rendering, the Redefer rdf2svg webservice is used. A nice and simple software package for vizualising RDF graphs with JavaScript is the visualRDF webservice.
Setup your own instance
eXist XML database
First of all install an instance of eXist on your local computer or a server of your choice. You can find the eXist packages and the installation
instructions on the eXist webpage: http://exist-db.org/exist/apps/homepage/index.html. Once eXist is installed and
running, grab the latest XTriples XAR file from here: http://download.spatialhumanities.de/ibr/. Alternatively you can
build the XAR file yourself from the latest sources on GitHub. Once you have the XAR, simply install it via the
eXist dashboard. Finally adapt the value of the $xtriplesWebserviceURL variable in extract.xql to the URL of your instance of XTriples.
Depending on how independent you want to run your instance of XTriples, you can optionally install local instances of the any23 and redefer webservices. If you do this
dont forget to adapt the $any23WebserviceURL, $redeferWebserviceURL and $redeferWebserviceRulesURL in extract.xql to the URLs on which you run
these webservices.
Any23 webservice
You can download the latest version of Apache Any23 right here: https://any23.apache.org/download.html. Check out the installation instructions.
Redefer webservice
You can download and install the latest version of the Redefer rdf2svg from here: https://github.com/rhizomik/redefer-rdf2svg.
Outline
Schema
Check out the RelaxNG schema for an exact documentation of all configuration options.